On a previous post, I have mentioned what is called the separation problem [1]. It can happen for example in a logistic regression, when a predictor (or combination of predictors) can perfectly predicts (separate) the data, leading to infinite Maximum Likelihood Estimate (MLE) due to a flat likelihood.
I also mentioned that one (possibly) naive solution to the problem could be to blindly exclude the predictors responsible for the problem. Other more elegant solutions include a penalized likelihood approach [1] and the use of weakly informative priors [2]. In this post, I would like to discuss the latter.
Model setup
Our model of interest here is a simple logistic regression


and since we are talking about Bayesian statistics the only thing left to complete our model specification is to assign prior distributions to 
Weakly informative priors
The idea proposed by Andrew Gelman and co-authors in [2] is to use minimal generic prior knowledge, enough to regularize the extreme inference that are obtained from maximum likelihood estimation. More specifically, they realized that we rarely encounter situations where a typical change in an input 


After some experimentation they settled with a Cauchy prior with scale parameter equal to 
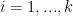
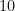
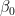
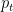

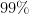
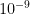
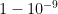
There is also a nice (and important) discussion about the pre-processing of input variables in [2] that I will keep for a future post.
Conclusion
I am in favor of the idea behind weakly informative priors. If we have some sensible information about the problem at hand we should find a way to encode it in our models. And Bayesian statistics provides an ideal framework for such a task. In the particular case of the separation problem in logistic regression, it was able to avoid the infinite estimates obtained with MLE and give sensible solutions to a variety of problems just by adding sensible generic information relevant to logistic regression.
References:
[1] Zorn, C. (2005). A solution to separation in binary response models. Political Analysis, 13(2), 157-170.
[2] Gelman, A., Jakulin, A., Pittau, M.G. and Su, Y.S. (2008). A weakly informative default prior distribution for logistic and other regression models. The Annals of Applied Statistics, 1360-1383.
 .
.
 is the logistic function (also called sigmoid function). Its cost function is given by
is the logistic function (also called sigmoid function). Its cost function is given by ![\displaystyle J(\theta) = -\frac{1}{m} \left[\sum_{i=1}^{m} y^{(i)} \log h_{\theta}(x^{(i)}) + (1 - y^{(i)}) \log (1 - h_{\theta}(x^{(i)}))\right] \ \ \ \ \ (1)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+J%28%5Ctheta%29+%3D+-%5Cfrac%7B1%7D%7Bm%7D+%5Cleft%5B%5Csum_%7Bi%3D1%7D%5E%7Bm%7D+y%5E%7B%28i%29%7D+%5Clog+h_%7B%5Ctheta%7D%28x%5E%7B%28i%29%7D%29+%2B+%281+-+y%5E%7B%28i%29%7D%29+%5Clog+%281+-+h_%7B%5Ctheta%7D%28x%5E%7B%28i%29%7D%29%29%5Cright%5D+%5C+%5C+%5C+%5C+%5C+%281%29&bg=ffffff&fg=000000&s=0&c=20201002)
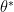 that minimizes Eq. (
that minimizes Eq. ( for new values of
for new values of 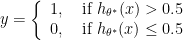

 is linear on the features
is linear on the features  , the decision boundary will be linear, which might not be adequate to represent the data. Non-linear boundaries can be obtained using non-linear features, as in
, the decision boundary will be linear, which might not be adequate to represent the data. Non-linear boundaries can be obtained using non-linear features, as in 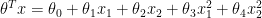 for example.
for example. for each class
for each class  to predict the probability that
to predict the probability that 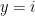 .
. .
. ), but fail to generalize to new examples. This is called overfitting. One possible solution to overfitting is to keep all features, but reduce magnitude/values of parameters
), but fail to generalize to new examples. This is called overfitting. One possible solution to overfitting is to keep all features, but reduce magnitude/values of parameters 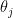 . This works well when we have a lot of features, each of which contributes a bit to predicting
. This works well when we have a lot of features, each of which contributes a bit to predicting  to penalize high values of
to penalize high values of  . One possibility is to add the penalty term
. One possibility is to add the penalty term 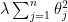 , where
, where ![\displaystyle J(\theta) = \frac{1}{m} \left[\sum_{i=1}^{m} (h_\theta (x^{(i)}) - y^{(i)})^2 + \lambda \sum_{j=1}^{n}\theta_j^2\right],](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+J%28%5Ctheta%29+%3D+%5Cfrac%7B1%7D%7Bm%7D+%5Cleft%5B%5Csum_%7Bi%3D1%7D%5E%7Bm%7D+%28h_%5Ctheta+%28x%5E%7B%28i%29%7D%29+-+y%5E%7B%28i%29%7D%29%5E2+%2B+%5Clambda+%5Csum_%7Bj%3D1%7D%5E%7Bn%7D%5Ctheta_j%5E2%5Cright%5D%2C&bg=ffffff&fg=000000&s=0&c=20201002)
![\displaystyle J(\theta) = -\frac{1}{m} \left[\sum_{i=1}^{m} y^{(i)} \log h_{\theta}(x^{(i)}) + (1 - y^{(i)}) \log (1 - h_{\theta}(x^{(i)}))\right] + \frac{\lambda}{2m} \sum_{j=1}^{n}\theta_j^2.](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+J%28%5Ctheta%29+%3D+-%5Cfrac%7B1%7D%7Bm%7D+%5Cleft%5B%5Csum_%7Bi%3D1%7D%5E%7Bm%7D+y%5E%7B%28i%29%7D+%5Clog+h_%7B%5Ctheta%7D%28x%5E%7B%28i%29%7D%29+%2B+%281+-+y%5E%7B%28i%29%7D%29+%5Clog+%281+-+h_%7B%5Ctheta%7D%28x%5E%7B%28i%29%7D%29%29%5Cright%5D+%2B+%5Cfrac%7B%5Clambda%7D%7B2m%7D+%5Csum_%7Bj%3D1%7D%5E%7Bn%7D%5Ctheta_j%5E2.&bg=ffffff&fg=000000&s=0&c=20201002)
