This post deals with the basics of character strings in R. My main reference has been Gaston Sanchez‘s ebook [1], which is excellent and you should read it if interested in manipulating text in R. I got the encoding’s section from [2], which is also a nice reference to have nearby. Text analysis will be one topic of interest to this Blog, so expect more posts about it in the near future.
Creating character strings
The class of an object that holds character strings in R is “character”. A string in R can be created using single quotes or double quotes.
chr = 'this is a string'
chr = "this is a string"
chr = "this 'is' valid"
chr = 'this "is" valid'
We can create an empty string with empty_str = "" or an empty character vector with empty_chr = character(0). Both have class “character” but the empty string has length equal to 1 while the empty character vector has length equal to zero.
empty_str = ""
empty_chr = character(0)
class(empty_str)
[1] "character"
class(empty_chr)
[1] "character"
length(empty_str)
[1] 1
length(empty_chr)
[1] 0
The function character() will create a character vector with as many empty strings as we want. We can add new components to the character vector just by assigning it to an index outside the current valid range. The index does not need to be consecutive, in which case R will auto-complete it with NA elements.
chr_vector = character(2) # create char vector
chr_vector
[1] "" ""
chr_vector[3] = "three" # add new element
chr_vector
[1] "" "" "three"
chr_vector[5] = "five" # do not need to
# be consecutive
chr_vector
[1] "" "" "three" NA "five"
Auxiliary functions
The functions as.character() and is.character() can be used to convert non-character objects into character strings and to test if a object is of type “character”, respectively.
Strings and data objects
R has five main types of objects to store data: vector, factor, multi-dimensional array, data.frame and list. It is interesting to know how these objects behave when exposed to different types of data (e.g. character, numeric, logical).
vector: Vectors must have their values all of the same mode. If we combine mixed types of data in vectors, strings will dominate.arrays: A matrix, which is a 2-dimensional array, have the same behavior found in vectors.data.frame: By default, a column that contains a character string in it is converted to factors. If we want to turn this default behavior off we can use the argument stringsAsFactors = FALSE when constructing the data.frame object.list: Each element on the list will maintain its corresponding mode.
# character dominates vector
c(1, 2, "text")
[1] "1" "2" "text"
# character dominates arrays
rbind(1:3, letters[1:3])
[,1] [,2] [,3]
[1,] "1" "2" "3"
[2,] "a" "b" "c"
# data.frame with stringsAsFactors = TRUE (default)
df1 = data.frame(numbers = 1:3, letters = letters[1:3])
df1
numbers letters
1 1 a
2 2 b
3 3 c
str(df1, vec.len=1)
'data.frame': 3 obs. of 2 variables:
$ numbers: int 1 2 ...
$ letters: Factor w/ 3 levels "a","b","c": 1 2 ...
# data.frame with stringsAsFactors = FALSE
df2 = data.frame(numbers = 1:3, letters = letters[1:3],
stringsAsFactors = FALSE)
df2
numbers letters
1 1 a
2 2 b
3 3 c
str(df2, vec.len=1)
'data.frame': 3 obs. of 2 variables:
$ numbers: int 1 2 ...
$ letters: chr "a" ...
# Each element in a list has its own type
list(1:3, letters[1:3])
[[1]]
[1] 1 2 3
[[2]]
[1] "a" "b" "c"
Character encoding
R provides functions to deal with various set of encoding schemes. The Encoding() function returns the encoding of a string. iconv() converts the encoding.
chr = "lá lá"
Encoding(chr)
[1] "UTF-8"
chr = iconv(chr, from = "UTF-8",
to = "latin1")
Encoding(chr)
[1] "latin1"
References:
[1] Gaston Sanchez’s ebook on Handling and Processing Strings in R.
[2] R Programming/Text Processing webpage.
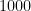 rows, where each row has information about the credit status of an individual, which can be good or bad. Besides, it has qualitative and quantitative information about the individuals. Examples of qualitative information are purpose of the loan and sex while examples of quantitative information are duration of the loan and installment rate in percentage of disposable income.
rows, where each row has information about the credit status of an individual, which can be good or bad. Besides, it has qualitative and quantitative information about the individuals. Examples of qualitative information are purpose of the loan and sex while examples of quantitative information are duration of the loan and installment rate in percentage of disposable income.
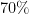 of the individuals being classified as having good credit. Therefore, the accuracy of a classification model should be superior to
of the individuals being classified as having good credit. Therefore, the accuracy of a classification model should be superior to 