I recently read the translation of Daniel Bernoulli’s paper from 1738. His work on utility function and measurement of risk was translated into english with the title “Exposition of a new theory on the measurement of risk” and published in Econometrica in 1954 [1]. This work is also contained in [2], which is an excellent book I recently acquired. The paper is easy to read and yet very powerful, specially if we consider it was written in 1738(!) with Daniel Bernoulli at age 25. The paper proposes the notion of declining marginal utility and its implications on decision making, and is considered a fundamental piece within modern decision theory.
Declining marginal utility
Prior to this work, it was assumed that decisions were made on an expected value or linear utility basis. Bernoulli then developed the concept of declining marginal utility, which lead to the logarithmic utility. The general idea of declining marginal utility, also referred to as “risk aversion” or “concavity” is crucial in modern decision theory.
He criticized the notion of linear utility with the following simple and intuitive example: Assume a lottery ticket pays 


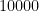

He then goes on to redefine the concept of value to a more general one. “The determination of the value of an item must not be based on its price, but rather on the utility it yields. The price of the item is dependent only on the thing itself and is equal for everyone; the utility, however, is dependent on the particular circumstances of the person making the estimate. Thus there is no doubt that a gain of one thousand ducats is more significant to a pauper than to a rich man though both gain the same amount.”
He then goes on and postulate that “it is highly probable that any increase in wealth, no matter how insignificant, will always result in an increase in utility which is inversely proportionate to the quantity of goods already possessed.” That is, he not only presented the notion of declining marginal utility but also proposes a specific functional form [3], namely
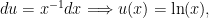
hence the logarithmic utility function. The conclusion is then that a decision must be made based on expected utility rather than on expected value.
Practical applications
The paper also provides an interesting overview of the applicability of the notion of declining marginal utility. For example, in gambling he concludes that “anyone who bet any part of his fortune, however small, on a mathematically fair game of chance acts irrationally”, since the expected utility will be smaller than the original sum of money possessed by the gamblers. He also proposed an exercise to inquire how great an advantage the gambler must enjoy over his opponent in order to avoid any expected loss. His result also shows mathematically the widely acceptable fact that “it may be reasonable for some individuals to invest in a doubtful enterprise and yet be unreasonable for others to do so”.
Using a merchant example, he computes how much wealth one should have to abstain from insuring his assets, or else what is the minimum fortune a man must have to justify offering insurance to other. Again, due to a declining marginal utility, one acts rationally by buying an insurance for a premium that is higher than the expected value of the transaction (risk aversion), a situation commonly seen in practice (otherwise insurance companies wouldn’t make money).
He also demonstrated mathematically the benefits one gets by investment diversification. And if all these were not enough, his ideas shed light on the St. Petersburg paradox.
Conclusion
Although written in 

References:
[1] Bernoulli, D. (1954). Exposition of a new theory on the measurement of risk. Econometrica: Journal of the Econometric Society, 23-36.
[2] MacLean, L. C., Thorp, E. O., and Ziemba, W. T. (Eds.). (2010). The Kelly capital growth investment criterion: Theory and practice (Vol. 3). world scientific.
[3] Lengwiler, Y. (2009). The Origins of Expected Utility Theory. In Vinzenz Bronzin’s Option Pricing Models (pp. 535-545). Springer Berlin Heidelberg.
 to the class
to the class  with highest posterior probability
with highest posterior probability  . It minimizes the total probability of misclassification. To compute
. It minimizes the total probability of misclassification. To compute  follows a Gaussian distribution with class-specific mean
follows a Gaussian distribution with class-specific mean 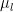 and common covariance matrix
and common covariance matrix  .
. 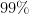 of the between-group variance in the
of the between-group variance in the 
 of the total variability in the data.
of the total variability in the data.