Here goes a little bit of my late experiences with R scripts. Comments, suggestions and/or opinions are welcome.
- Usefulness of R scripts
- Basic R script
- Processing command-line arguments
- Verbose mode and stderr
- stdin in a non-interactive mode
Besides being an amazing interactive tool for data analysis, R software commands can also be executed as scripts. This is useful for example when we need to work in large projects where different parts of the project needs to be implemented using different languages that are later glued together to form the final product.
In addition, it is extremely useful to be able to take advantage of pipeline capabilities of the form
cat file.txt | preProcessInPython.py | runRmodel.R | formatOutput.sh > output.txt
and design your tasks following the Unix philosophy:
Write programs that do one thing and do it well. Write programs to work together. Write programs to handle text streams, because that is a universal interface. — Doug McIlroy
A basic template for an R script is given by
#! /usr/bin/env Rscript # R commands here
To start with a simple example, create a file myscript.R and include the following code on it:
#! /usr/bin/env Rscript x <- 5 print(x)
Now go to your terminal and type chmod +x myscript.R to give the file execution permission. Then, execute your first script by typing ./myscript.R on the terminal. You should see
[1] 5
displayed on your terminal since the result is by default directed to stdout. We could have written the output of x to a file instead, of course. In order to do this just replace the print(x) statement by some writing command, as for example
output <- file("output_file.txt", "w")
write(x, file = output)
close(output)
which will write 5 to output_file.txt.
Processing command-line arguments
There are different ways to process command-line arguments in R scripts. My favorite so far is to use the getopt package from Allen Day and Trevor L. Davis. Type
require(devtools)
devtools::install_github("getopt", "trevorld")
in an R environment to install it on your machine. To use getopt in your R script you need to specify a 4 column matrix with information about the command-line arguments that you want to allow users to specify. Each row in this matrix represent one command-line option. For example, the following script allows the user to specify the output variable using the short flag -x or the long flag --xValue.
#! /usr/bin/env Rscript
require("getopt", quietly=TRUE)
spec = matrix(c(
"xValue" , "x", 1, "double"
), byrow=TRUE, ncol=4)
opt = getopt(spec);
if (is.null(opt$xValue)) {
x <- 5
} else {
x <- opt$xValue
}
print(x)
As you can see above the spec matrix has four columns. The first defines the long flag name xValue, the second defines the short flag name x, the third defines the type of argument that should follow the flag (0 = no argument, 1 = required argument, 2 = optional argument.), the fourth defines the data type to which the flag argument shall be cast (logical, integer, double, complex, character) and there is a possible 5th column (not used here) that allow you to add a brief description of the purpose of the option. Now our myscript.R accepts command line arguments:
./myscript.R [1] 5 myscript.R -x 7 [1] 7 myscript.R --xValue 9 [1] 9
We can also create a verbose flag and direct all verbose comments to stderr instead of stdout, so that we don’t mix what is the output of the script with what is informative messages from the verbose option. Following is an illustration of a verbose flag implementation.
#! /usr/bin/env Rscript
require("getopt", quietly=TRUE)
spec = matrix(c(
"xValue" , "x", 1, "double",
"verbose", "v", 0, "logical"
), byrow=TRUE, ncol=4)
opt = getopt(spec);
if (is.null(opt$xValue)) {
x <- 5
} else {
x <- opt$xValue
}
if (is.null(opt$verbose)) {
verbose <- FALSE
} else {
verbose <- opt$verbose
}
if (verbose) {
write("Verbose going to stderr instead of stdout",
stderr())
}
write(x, file = stdout())
We have now two possible flags to specify in our myscript.R:
./myscript.R 5 ./myscript.R -x 7 7 ./myscript.R -x 7 -v Verbose going to stderr instead of stdout 7
The main difference of directing verbose messages to stderr instead of stdout appear when we pipe the output to a file. In the code below the verbose message appears on the terminal and the value of x goes to the output_file.txt, as desired.
./myscript.R -x 7 -v > output_file.txt Verbose going to stderr instead of stdout cat output_file.txt 7
stdin in a non-interactive mode
The take fully advantage of the pipeline capabilities that I have mentioned at the beginning of this post, it is useful to accept input from stdin. For example, a template of a script that reads one line at a time from stdin could be
input_con <- file("stdin")
open(input_con)
while (length(oneLine <- readLines(con = input_con,
n = 1,
warn = FALSE)) > 0) {
# do something one line at a time ...
}
close(input_con)
Note that when we are running our R scripts from the terminal we are in a non-interactive mode, which means that
input_con <- stdin()
would not work as expected on the template above. As described on the help page for stdin():
stdin() refers to the ‘console’ and not to the C-level ‘stdin’ of the process. The distinction matters in GUI consoles (which may not have an active ‘stdin’, and if they do it may not be connected to console input), and also in embedded applications. If you want access to the C-level file stream ‘stdin’, use file(“stdin”).
And that is the reason I used
input_con <- file("stdin")
open(input_con)
instead. Naturally, we could allow the data to be inputted from stdin by default while making a flag available in case the user wants to provide a file path containing the data to be read. Below is a template for this:
spec = matrix(c(
"data" , "d" , 1, "character"
), byrow=TRUE, ncol=4);
opt = getopt(spec);
if (is.null(opt$data)) {
data_file <- "stdin"
} else {
data_file <- opt$data
}
if (data_file == "stdin"){
input_con <- file("stdin")
open(input_con)
data <- read.table(file = input_con, header = TRUE,
sep = "\t", stringsAsFactors = FALSE)
close(input_con)
} else {
data <- read.table(file = data_file, header = TRUE,
sep = "\t", stringsAsFactors = FALSE)
}
References:
[1] Relevant help pages, as ?Rscript for example.
[2] Reference manual of the R package getopt.
 to the class
to the class  with highest posterior probability
with highest posterior probability  . It minimizes the total probability of misclassification. To compute
. It minimizes the total probability of misclassification. To compute  follows a Gaussian distribution with class-specific mean
follows a Gaussian distribution with class-specific mean 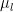 and common covariance matrix
and common covariance matrix  .
. 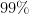 of the between-group variance in the
of the between-group variance in the 
 of the total variability in the data.
of the total variability in the data.