Here are my notes regarding Chapter 2 of The elements of statistical learning: data mining, inference and prediction.
This chapter illustrates many useful concepts in statistics using two simple models as example. It compares the performance of linear models fitted through least square technique with the 
Effective number of parameters
At first, it might seem that 

Expected prediction error and Squared loss function
Usually, in our data analysis problems, we seek a function 


It was shown that under squared error loss, the expected prediction error,

taken wrt the joint distribution 


Both
- Least squares assumes
is well approximated by a globally linear function.
Looking at this difference, we might feel that least squares is very restrictive while the 


Limited sample sizes
First of all we often do not have very large samples. If the linear or some more structured model is appropriate, then we can usually get a more stable estimate than
Curse of dimensionality
It would seem that with a reasonably large set of training data, we could always approximate the theoretically optimal conditional expectation by 
There are many manifestations of this problem, and a few of them were described:
- Consider the nearest-neighbor procedure for inputs uniformly distributed in a
, we must cover 63% or 80% of the range of each input variable. Such neighborhoods are no longer “local”. Reducing the percentage of the data covered dramatically does not help much either, since the fewer observations we average, the higher is the variance of our fit.
- Consider
data points uniformly distributed in a
- Another manifestation of the curse is that the sampling density is proportional to
, where
represents a dense sample for a single input problem, then
is the sample size required for the same sampling density with
inputs. Thus in high dimensions all feasible training samples sparsely populate the input space.
Going back to our objective of estimating the function
By imposing some heavy restrictions on the class of models being fitted, we can avoid the curse of dimensionality.
Structured Regression Models
Although nearest-neighbor and other local methods focus directly on estimating the function at a point, they face problems in high-dimensions. They may also be inappropriate even in low dimensions in cases where more structured approaches can make more efficient use of the data.
The choice of finding a function 
Any method that attempts to produce locally varying functions in small isotropic neighborhoods will run into problems in high dimensions, again the curse of dimensionality. And conversely, all methods that overcome the dimensionality problems have an associated, and often implicit or adaptive, metric for measuring neighborhoods, which basically does not allow the neighborhood to be simultaneously small in all directions.
Classes of Restricted Estimators
The variety of nonparametric regression techniques or learning methods fall into a number of different classes depending on the nature of the restrictions imposed. These classes are not distinct, and indeed some methods fall in several classes. Each of the classes has associated with it one or more parameters, sometimes appropriately called smoothing parameters, that control the effective size of the local neighborhood. In the book they describe three broad classes.
- Roughness Penalty and Bayesian Methods: Here the class of functions is controlled by explicitly penalizing
with a roughness penalty
The user-selected functional
will be large for functions
- Kernel Methods and Local Regression: These methods can be thought of as explicitly providing estimates of the regression function or conditional expectation by specifying the nature of the local neighborhood, and of the class of regular functions fitted locally. The local neighborhood is specified by a kernel function
which assigns weights to points
. In general we can define a local regression estimate of
as
, where
minimizes
and
is some parameterized function, such as a low-order polynomial.
- Basis Functions and Dictionary Methods: The model for
where each of the
is a function of the input
. Adaptively chosen basis function methods are also known as dictionary methods, where one has available a possibly infinite set or dictionary
of candidate basis functions from which to choose, and models are built up by employing some kind of search mechanism.



Expected prediction error for categorical variable
What do we do when the output is a categorical variable 




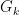

With this 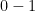

This reasonable solution is known as the Bayes classifier, and says that we classify to the most probable class, using the conditional (discrete) distribution 
The email/spam example illustrate well the point that in a statistical problem not all the errors are necessarily equal. We want to avoid filtering out good email, while letting spam get through is not desirable but less serious in its consequences.
Bias-variance trade-off
The linear decision boundary from least squares is very smooth, and apparently stable to fit. It does appear to rely heavily on the assumption that a linear decision boundary is appropriate. It has low variance and potentially high bias. On the other hand, the
Typically we would like to choose our model complexity to trade bias off with variance in such a way as to minimize the test error. An obvious estimate of test error is the training error 
Chapter 7 of the book will discuss methods for estimating the test error of a prediction method, and hence estimating the optimal amount of model complexity for a given prediction method and training set.
References:
– Hastie, T., Tibshirani, R., Friedman, J. (2009). The elements of statistical learning: data mining, inference and prediction. Springer. (Chapter 2)
– Bellman, R. E. (1961). Adaptive Control Processes, Princeton University Press.

