Principal component analysis (PCA) is a dimensionality reduction technique that is widely used in data analysis. Reducing the dimensionality of a dataset can be useful in different ways. For example, our ability to visualize data is limited to 2 or 3 dimensions. Lower dimension can sometimes significantly reduce the computational time of some numerical algorithms. Besides, many statistical models suffer from high correlation between covariates, and PCA can be used to produce linear combinations of the covariates that are uncorrelated between each other.
More technically …
Assume you have  observations of
observations of  different variables. Define
different variables. Define  to be a
to be a 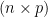 matrix where the
matrix where the  -th column of contains the observations of the -th variable,
-th column of contains the observations of the -th variable,  . Each row
. Each row  of can be represented as a point in a -dimensional space. Therefore, contains points in a -dimensional space.
of can be represented as a point in a -dimensional space. Therefore, contains points in a -dimensional space.
PCA projects -dimensional data into a  -dimensional sub-space
-dimensional sub-space 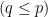 in a way that minimizes the residual sum of squares (RSS) of the projection. That is, it minimizes the sum of squared distances from the points to their projections. It turns out that this is equivalent to maximizing the covariance matrix (both in trace and determinant) of the projected data ([1], [2]).
in a way that minimizes the residual sum of squares (RSS) of the projection. That is, it minimizes the sum of squared distances from the points to their projections. It turns out that this is equivalent to maximizing the covariance matrix (both in trace and determinant) of the projected data ([1], [2]).
Assume  to be the covariance matrix associated with . Since is a non-negative definite matrix, it has an eigendecomposition
to be the covariance matrix associated with . Since is a non-negative definite matrix, it has an eigendecomposition

where  is a diagonal matrix of (non-negative) eigenvalues in decreasing order, and
is a diagonal matrix of (non-negative) eigenvalues in decreasing order, and  is a matrix where its columns are formed by the eigenvectors of . We want the first principal component
is a matrix where its columns are formed by the eigenvectors of . We want the first principal component 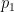 to be a linear combination of the columns of ,
to be a linear combination of the columns of , 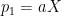 , subject to
, subject to  . In addition, we want to have the highest possible variance
. In addition, we want to have the highest possible variance 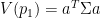 . It turns out that
. It turns out that  will be given by the column eigenvector corresponding with the largest eigenvalue of (a simple proof of this can be found in [2]). Taking subsequent eigenvectors gives combinations with as large as possible variance that are uncorrelated with those that have been taken earlier.
will be given by the column eigenvector corresponding with the largest eigenvalue of (a simple proof of this can be found in [2]). Taking subsequent eigenvectors gives combinations with as large as possible variance that are uncorrelated with those that have been taken earlier.
If we pick the first principal components, we have projected our -dimensional data into a -dimensional sub-space. We can define 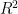 in this context to be the fraction of the original variance kept by the projected points,
in this context to be the fraction of the original variance kept by the projected points,

Some general advice
- PCA is not scale invariant, so it is highly recommended to standardize all the variables before applying PCA.
- Singular Value Decomposition (SVD) is more numerically stable than eigendecomposition and is usually used in practice.
- How many principal components to retain will depend on the specific application.
- Plotting
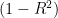 versus the number of components can be useful to visualize the number of principal components that retain most of the variability contained in the original data.
versus the number of components can be useful to visualize the number of principal components that retain most of the variability contained in the original data.
- Two or three principal components can be used for visualization purposes.
References:
[1] Venables, W. N., Brian D. R. Modern applied statistics with S-PLUS. Springer-verlag. (Section 11.1)
[2] Notes from a class given by Brian Junker and Cosma Shalizi at CMU.
