Modeling is one of the topics I will be writing a lot on this blog. Because of that I thought it would be nice to introduce some datasets that I will use in the illustration of models and methods later on. In this post I describe the German credit data [1], very popular within the machine learning literature.
This dataset contains 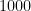
This dataset has also been described and used in [2] and is available in R through the caret package.
require(caret) data(GermanCredit)
The version above had all the categorical predictors converted to dummy variables (see for ex. Section 3.6 of [2]) and can be displayed using the str function:
str(GermanCredit, list.len=5) 'data.frame': 1000 obs. of 62 variables: $ Duration : int 6 48 12 ... $ Amount : int 1169 5951 2096 ... $ InstallmentRatePercentage : int 4 2 2 ... $ ResidenceDuration : int 4 2 3 ... $ Age : int 67 22 49 ... [list output truncated]
For data exploration purposes, I also like to keep a dataset where the categorical predictors are stored as factors rather than converted to dummy variables. This sometimes facilitates since it provides a grouping effect for the levels of the categorical variable. This grouping effect is lost when we convert them to dummy variables, specially when a non-full rank parametrization of the predictors is used.
The response (or target) variable here indicates the credit status of an individual and is stored in the column Class of the GermanCredit dataset as a factor with two levels, “Bad” and “Good”.

We can see above (code for Figure here) that the German credit data is a case of unbalanced dataset with 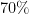
The nice thing about this dataset is that it has a lot of challenges faced by data scientists on a daily basis. For example, it is unbalanced, has predictors that are constant within groups and has collinearity among predictors. In order to fit some models to this dataset, like the LDA for example, we must deal with these challenges first. More on that later.
References:
[1] German credit data hosted by the UCI Machine Learning Repository.
[2] Kuhn, M., and Johnson, K. (2013). Applied Predictive Modeling. Springer.

Olá Thiago!
Parabéns pelo site! Descobri hoje e gostei muito.
Caso eu possa servir de alguma ajuda eu tinha um dos sites que mais cresceram em 2013 http://www.estatisti.co/ e agora parei para concluir minha monografia na ENCE!
Qualquer coisa é só falar!
Abraço e sucesso!
Oi Joao,
Obrigado. Muito legal o seu site. Bem profissional. Pretendo continuar nessa linha aqui no blog, mais informal mesmo, postando uma vez por semana sobre assuntos que me interessam em estatistica e analise de dados.
Vamos nos falando.
Um abs,
Pingback: Near-zero variance predictors. Should we remove them? ← Patient 2 Earn