As mentioned in Part I, estimation of the test error (or prediction error)  is our goal. After all, we are interested in an estimate of the error for the training sample we have at hand. However, it has been empirically shown that cross-validation, bootstrap and other related methods effectively estimate the expected error
is our goal. After all, we are interested in an estimate of the error for the training sample we have at hand. However, it has been empirically shown that cross-validation, bootstrap and other related methods effectively estimate the expected error  , obtained by averaging out everything that is random, including the training sample. See for example Section 7.12 of [1], where under a specific set-up it shows that cross-validation do a better job at estimating than it does for estimating .
, obtained by averaging out everything that is random, including the training sample. See for example Section 7.12 of [1], where under a specific set-up it shows that cross-validation do a better job at estimating than it does for estimating .
1. Cross-validation
Ideally, if we had enough data, we would set aside a validation set and use it to assess the performance of our prediction model. Since data are often scarce, this is usually not possible. Cross-validation can be used to overcome this difficulty. The idea is to split the data into  roughly equal-sized parts. For the
roughly equal-sized parts. For the  -th part, we fit the model to the other
-th part, we fit the model to the other  parts of the data, and calculate the prediction error of the fitted model when predicting the -th part of the data. We do this for
parts of the data, and calculate the prediction error of the fitted model when predicting the -th part of the data. We do this for  and combine the estimates of prediction error. Then the cross-validation estimate of prediction error is
and combine the estimates of prediction error. Then the cross-validation estimate of prediction error is

where  is the number of data points,
is the number of data points,  is the loss function,
is the loss function,  is the
is the  -th data point,
-th data point,  is the function that maps the observation to the group it belongs, and
is the function that maps the observation to the group it belongs, and  is the model trained with the dataset excluding the part.
is the model trained with the dataset excluding the part.
What is a good value for ?
What value should we choose for ? With  (also known as leave-one-out CV), the cross-validation estimator is approximately unbiased for the true (expected) prediction error, but can have high variance because the “training sets” are so similar to one another. The computational burden is also considerable, except for some special cases. On the other hand, with
(also known as leave-one-out CV), the cross-validation estimator is approximately unbiased for the true (expected) prediction error, but can have high variance because the “training sets” are so similar to one another. The computational burden is also considerable, except for some special cases. On the other hand, with  say, cross-validation has lower variance. But bias could be a problem, depending on how the performance of the learning method varies with the size of the training set. A good check here would be to plot (1 –
say, cross-validation has lower variance. But bias could be a problem, depending on how the performance of the learning method varies with the size of the training set. A good check here would be to plot (1 –  ) against the size of the training set to get a feeling on how your learning method performance varies with the sample size. If the learning curve has a considerable slope at the given training set size that you would use to perform, for example, a
) against the size of the training set to get a feeling on how your learning method performance varies with the sample size. If the learning curve has a considerable slope at the given training set size that you would use to perform, for example, a 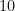 -CV, then it would overestimate the true prediction error. Whether this bias is a drawback in practice depends on the objective. Overall, five- or tenfold cross-validation are recommended as a good compromise (see [2] and [3]).
-CV, then it would overestimate the true prediction error. Whether this bias is a drawback in practice depends on the objective. Overall, five- or tenfold cross-validation are recommended as a good compromise (see [2] and [3]).
One-standard deviation rule for CV
Often a “one-standard error” rule is used with cross-validation, in which we choose the most parsimonious model whose error is no more than one standard error above the error of the best model. This would indicate that this more parsimonious model is not worse, at least not in a statistically significant way. Figure  of the book gives a good illustration of this.
of the book gives a good illustration of this.
What K-fold cross-validation estimates?
With or , we might guess that it estimates the expected error , since the training sets in each fold are quite different from the original training set. On the other hand, for leave-one-out CV we might guess that cross-validation estimates the conditional error . It turns out, as mentioned before, that cross-validation only estimates effectively the average error .
The right way to do CV!
In general, with a multistep modeling procedure, cross-validation must be applied to the entire sequence of modeling steps. In particular, samples must be “left out” before any selection or filtering steps are applied. For example, you shouldn’t use the whole dataset to select the best predictors out of hundreds you have available in a large scale problem, and then apply CV after this selection. This would give an unfair advantage for those selected predictors, which “have been exposed” to the entire dataset. Practices like this could grossly underestimate the expected prediction error.
However, initial unsupervised screening steps can be done before samples are left out. For example, we could select the 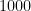 predictors with highest variance across all samples, before starting cross-validation. Since this filtering does not involve the response variable, it does not give the predictors an unfair advantage.
predictors with highest variance across all samples, before starting cross-validation. Since this filtering does not involve the response variable, it does not give the predictors an unfair advantage.
2. Bootstrap Methods
The bootstrap is a general tool for assessing statistical accuracy. Suppose we have a model fit to a set of training data. We denote the training set by  where
where  . The basic idea is to randomly draw datasets with replacement from the training data, each sample the same size as the original training set. This is done
. The basic idea is to randomly draw datasets with replacement from the training data, each sample the same size as the original training set. This is done  times (
times ( say), producing bootstrap datasets. Then we refit the model to each of the bootstrap datasets, and examine the behavior of the fits over the replications.
say), producing bootstrap datasets. Then we refit the model to each of the bootstrap datasets, and examine the behavior of the fits over the replications.
Assume  is any quantity computed from the data
is any quantity computed from the data  . For example, the prediction at some input point. From the bootstrap sampling we can estimate any aspect of the distribution of , as for example, its mean,
. For example, the prediction at some input point. From the bootstrap sampling we can estimate any aspect of the distribution of , as for example, its mean,

and variance
![\displaystyle \widehat{Var}[S(Z)] = \frac{1}{B-1} \sum_{b=1}^{B} (S(Z^{*b}) - \bar{S}^*)^2, \ \ \ \ \ (2)](https://s0.wp.com/latex.php?latex=%5Cdisplaystyle+%5Cwidehat%7BVar%7D%5BS%28Z%29%5D+%3D+%5Cfrac%7B1%7D%7BB-1%7D+%5Csum_%7Bb%3D1%7D%5E%7BB%7D+%28S%28Z%5E%7B%2Ab%7D%29+-+%5Cbar%7BS%7D%5E%2A%29%5E2%2C+%5C+%5C+%5C+%5C+%5C+%282%29&bg=ffffff&fg=000000&s=0&c=20201002)
where  is the
is the  -th training set randomly draw from the original training set. Note that Eqs. (1) and (2) can be thought of as Monte-Carlo estimate of the mean and variance of under sampling from the empirical distribution function
-th training set randomly draw from the original training set. Note that Eqs. (1) and (2) can be thought of as Monte-Carlo estimate of the mean and variance of under sampling from the empirical distribution function  for the data
for the data  .
.
How to estimate prediction error using bootstrap?
One approach would be to fit the model in question on a set of bootstrap samples, and then keep track of how well it predicts the original training set.

where  is the predicted value at
is the predicted value at  , from the model fitted to the -th bootstrap dataset.
, from the model fitted to the -th bootstrap dataset.
However, it is easy to see that  in Eq. (3) does not provide a good estimate in general. The reason is that the bootstrap datasets are acting as the training samples, while the original training set is acting as the test sample, and these two samples have observations in common. This overlap can make overfit predictions look unrealistically good, and is the reason that cross-validation explicitly uses non-overlapping data for the training and test samples.
in Eq. (3) does not provide a good estimate in general. The reason is that the bootstrap datasets are acting as the training samples, while the original training set is acting as the test sample, and these two samples have observations in common. This overlap can make overfit predictions look unrealistically good, and is the reason that cross-validation explicitly uses non-overlapping data for the training and test samples.
Improvements over
Modifications to have been proposed to overcome this problem, as the leave-one-out bootstrap estimate of prediction error  , in which for each observation, we only keep track of predictions from bootstrap samples not containing that observation. This would address the overfitting problem of , but it still suffers from training-set-size bias.
, in which for each observation, we only keep track of predictions from bootstrap samples not containing that observation. This would address the overfitting problem of , but it still suffers from training-set-size bias.
The average number of distinct observations in each bootstrap sample is about  , so its bias will roughly behave like that of twofold cross-validation. Thus if the learning curve has considerable slope at sample size
, so its bias will roughly behave like that of twofold cross-validation. Thus if the learning curve has considerable slope at sample size 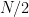 , the leave-one out bootstrap will be biased upward as an estimate of the true error. The “.632 estimator” is designed to alleviate this bias. It is defined by
, the leave-one out bootstrap will be biased upward as an estimate of the true error. The “.632 estimator” is designed to alleviate this bias. It is defined by

According to [1] the derivation of the  estimator is complex; intuitively it pulls the leave-one out bootstrap estimate down toward the training error rate
estimator is complex; intuitively it pulls the leave-one out bootstrap estimate down toward the training error rate  , and hence reduces its upward bias. The estimator works well in “light fitting” situations, but can break down in overfit ones [4].
, and hence reduces its upward bias. The estimator works well in “light fitting” situations, but can break down in overfit ones [4].
Summary
From the previous exposition, I would rather use CV instead of bootstrap to estimate prediction error. Bootstrap presents some shortcomings that require solutions that, from my point of view, are not easily understood and sometimes seems ad-hoc. For the particular problems and scenarios analysed on Chapter 7 of [1], AIC, CV and bootstrap yields models very close to the best available. Note that for the purpose of model selection, any of the measures could be biased and it wouldn’t affect things, as long as the bias did not change the relative performance of the methods. For example, the addition of a constant to any of the measures would not change the resulting chosen model. However, for complex models, estimation of the effective number of parameters is very difficult. This makes methods like AIC impractical and leaves us with cross-validation or bootstrap as the methods of choice.
However, if we are interested not in model selection but in the estimation of the prediction error, the conclusion was that AIC overestimated the prediction error of the chosen model, while CV and bootstrap were significantly more accurate. Hence the extra work involved in computing a cross-validation or bootstrap measure is worthwhile, if an accurate estimate of the test error is required.
References:
[1] Hastie, T., Tibshirani, R., Friedman, J. (2009). The elements of statistical learning: data mining, inference and prediction. Springer. (Chapter 7)
[2] Breiman, L. and Spector, P. (1992). Submodel selection and evaluation in regression: the X-random case. International Statistical Review, 60, 291-319.
[3] Kohavi, R. (1995). A study of cross-validation and bootstrap for accuracy estimation and model selection. International Joint Conference on Artificial Intelligence (IJCAI), p. 1137–1143.
[4] Breiman, L., Friedman, J., Olshen, R. and Stone, C. (1984). Classification and Regression Trees. Wadsworth, New York.
Related posts:
